



Random Forest is a classifier consisting of a set of tree-structured classifiers with identically distributed independent random vectors and each tree casting a unit vote at input x for the most popular class. A random vector that is independent of the previous random vectors of the same distribution is generated and a tree is generated using the training test, an upper bound is extracted for Random Forests to get the generalization error in terms of two exact parameters and interdependence of individual classifiers.
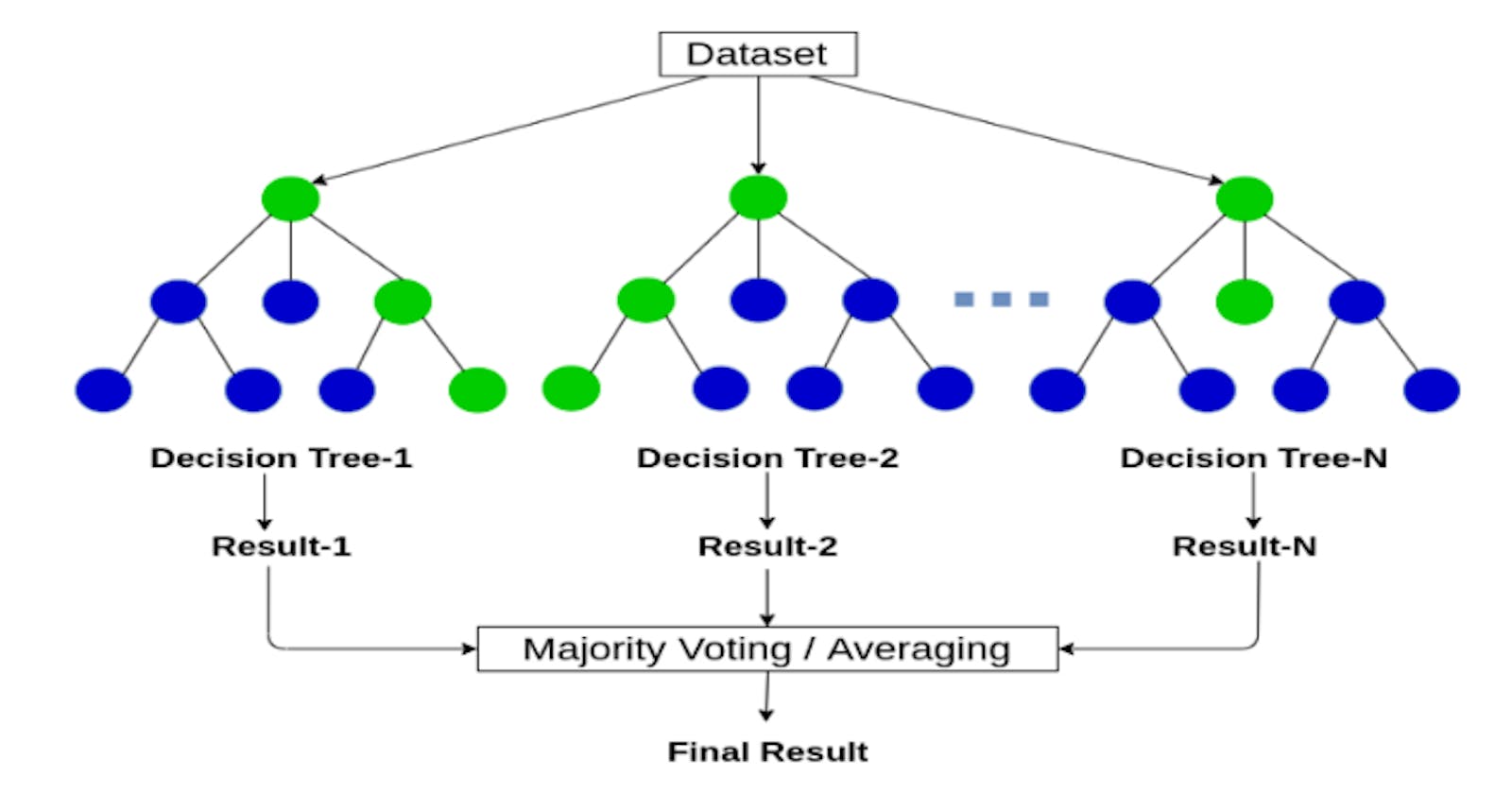
An integrated learning model with the Decision Tree basic classifier is Random Forest. To get multiple subsets of samples, it implements the bootstrap method, creates a decision tree utilizing each subset of samples, and combines several Decision Trees into a Random Forest. When the sample to be classified is reached, the final outcome of the classification is decided by a vote on the Decision Tree. Generally, scholars increase the precision of the classifier starting from the classifier and reduce the association between classifiers. Random Forest algorithm in the classification process, where the effects of the classification of each base classifier have a common distribution of errors, the final reduction of the classification effect is accomplished. Takes the test characteristics and uses the rules of each randomly generated Decision Tree to forecast the result and store the expected result (target). Determine the votes for each predicted goal. Consider the predicted high-voted goal as the final prediction from the Random Forest algorithm
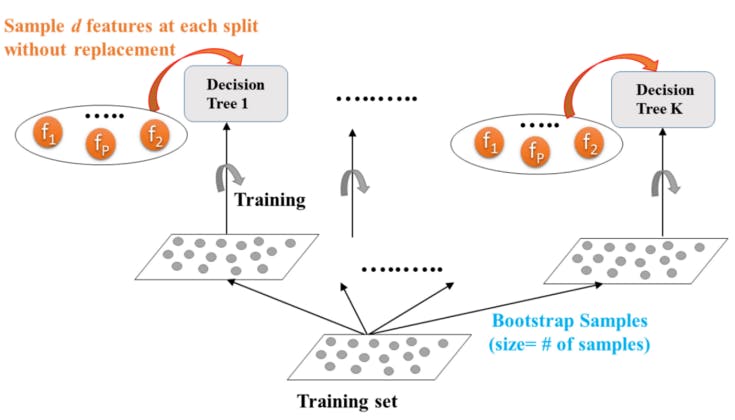
The Random Forest algorithm is a Decision Tree-based classifier. It selects the best classification tree as the classification algorithm of the final classifier by voting. It can be used for both classifications and regression tasks. It provides higher accuracy through cross-validation. Currently, it is in news classification, intrusion detection, content information filtering, and sentiment analysis, there is a wide range of applications in the field of image processing. Let’s look at some examples of Random Forest regressors for a bike sharing demand dataset where X_train,y_train, X_test, and y_test have split from the original dataset.
# Import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
# Instantiate rf
rf = RandomForestRegressor(n_estimators=25,
random_state=2)
# Fit rf to the training set
rf.fit(X_train, y_train)
# Import mean_squared_error as MSE
from sklearn.metrics import mean_squared_error as MSE
# Predict the test set labels
y_pred = rf.predict(X_test)
# Evaluate the test set RMSE
rmse_test = MSE(y_test,y_pred)**(1/2)
# Print rmse_test
print('Test set RMSE of rf: {:.2f}'.format(rmse_test))
Test set RMSE of rf: 51.86
If we were to train a single CART on the same dataset and compare it to rf, the test set RMSE achieved by rf would be significantly smaller.
We can further use this for feature selection which will help improve our model. For this, I created a pandas.Series object called importances containing the feature names as index and their importances as values. In addition, matplotlib.pyplot is available as plt and pandas as pd.
# Create a pd.Series of features importances
importances = pd.Series(data=rf.feature_importances_,
index= X_train.columns)
# Sort importances
importances_sorted = importances.sort_values()
# Draw a horizontal barplot of importances_sorted
importances_sorted.plot(kind='barh', color='blue')
plt.title('Features Importances')
plt.show()
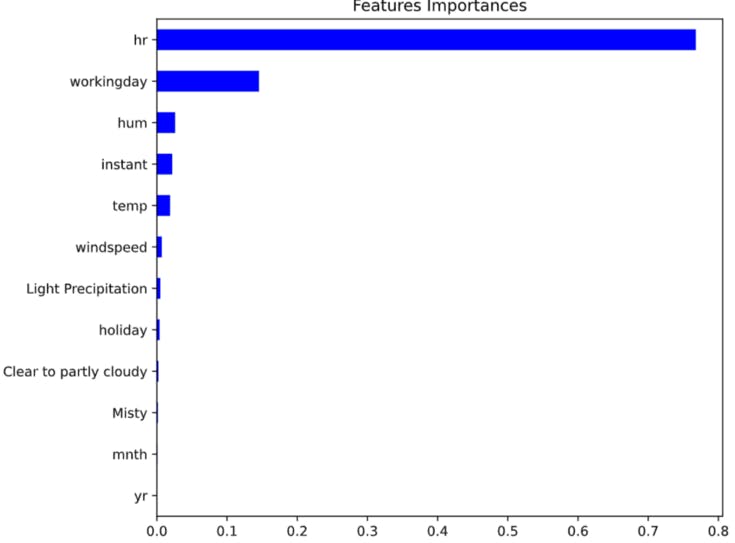
We can see that hr and working day are the most important features according to rf. The importances of these two features add up to more than 90%.
As always, Happy Hacking!